
Microsoft Teams For Linux Forensics - Part 1
The Beginning of the Journey
I’d just wrapped up a technical interview, and out of nowhere, I felt like reaching out to the person who interviewed me. But here’s the twist — I had joined the Microsoft Teams call as a guest. No login, no notes, nothing. By the time I reopened Teams, poof — the session was gone. So was the name, the email, the chat… everything.
That little hiccup got me thinking: Is it even possible to recover any of that info? And down the rabbit hole I went.
What is Microsoft Teams For Linux?
On December 10, 2019, Microsoft did something unexpected — it announced Microsoft Teams for Linux. For the Linux community, this was big. Finally, a native Microsoft 365 app with proper .deb and .rpm packages, no Wine tricks or browser workarounds. The app was built on Electron, offering core features like chat, meetings, and notifications. It wasn’t perfect, but it worked — and more importantly, it felt like Linux was finally being taken seriously in the modern workplace stack.
But the excitement was short-lived. In 2022, Microsoft quietly announced it was discontinuing the Teams desktop app for Linux, with support ending by year’s end. Instead, they recommended using the Teams Progressive Web App (PWA) via a browser. Just like that, the brief era of native Teams on Linux was over — leaving many users disappointed and heading back to Chrome tabs for their daily meetings.
We hear from you that you want the full richness of Microsoft Teams features on Linux such as background effects, reactions, gallery view, etc. We found the best way to act on this is to offer a Teams progressive web app (PWA) on Linux as a new feature of our current web client, which we’ll make available to our Linux customers in the coming months. PWA enables us to ship the latest Teams features faster to our Linux customers and helps us bridge the gaps that existed between the Teams desktop client on Linux and Windows. The PWA experience will be available on both Edge and Chrome browsers on Linux.
—–Microsoft
However, the Linux community doesn’t give up that easily — thanks to open-source contributor Ismael Martinez, we now have a solid, community-driven alternative: teams-for-linux. It’s available via the Snap Store, actively maintained, and still brings Teams to the Linux desktop.
How it works?
The app is not built from scratch like the original Microsoft Teams native app — instead, it wraps the web version of Teams inside an Electron shell, making it feel like a desktop app. This allows Linux users to launch Teams like any other native app, with its own window, icon, notifications, etc.
However, because it relies entirely on the Microsoft Teams web interface, the app can only do what the web version allows. ok! what is this electron?
What is electron?
Electron is an open-source framework that lets developers build cross-platform desktop applications using web technologies — mainly HTML, CSS, and JavaScript. At its core, Electron combines:
- Frontend: Chromium (the engine behind Google Chrome) to render the UI, and
- Backend: Node.js to access system-level features like the file system, OS APIs, etc.
In our case, the Teams for Linux app is essentially a browser window — built with Electron — that loads the Microsoft Teams web version, but without the address bar or browser controls. It looks and feels like a native desktop app, but behind the scenes, it’s just the web version of Teams running inside a lightweight wrapper.
Filesystem Layout & Artifact Locations (Snap Install)
Its very easy to install teams-for-linux on ubuntu using the following command.
snap install teams-for-linux
Once you install teams-for-linux(/snap/bin/teams-for-linux) via Snap, the application stores its files primarily in two locations on the system:
-
System-Wide: SNAP_DATA: /snap/teams-for-linux/ : contains the actual application binaries, static resources, .desktop files, libraries,desktop environment scripts,Localization files, etc.
-
User-Wide: ~/snap/teams-for-linux/ or /home/<user>/snap/teams-for-linux : - This is user-specific writable data directory, which holds runtime data, configuration, logs, and other artifacts like Cookies, leveldb files, etc.
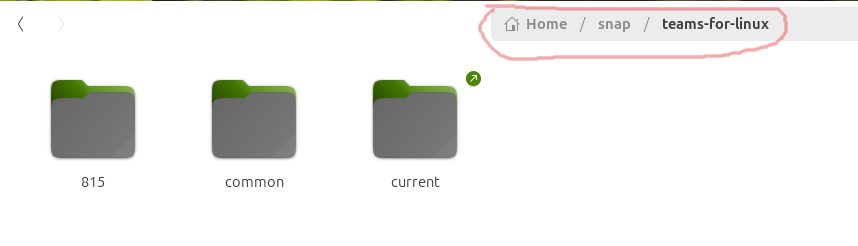
From a digital forensics perspective, the User-Wide location location (~/snap/teams-for-linux/) is especially relevant. This is where you’ll find potentially valuable artifacts such as application logs, cache files, local storage, chat history, cookies, etc.
let’s understand what each folder means.
<revision>(ex:815) - This represents the specific version number of the teams-for-linux Snap package installed on the system. Snap packages maintain multiple older revisions locally. By default, 2 revisions are stored locally, during an update, the system installs the new revision while retaining the previous one.
common - This folder contains data shared across all versions of the snap package.
current - This is a symbolic link (shortcut) that points to the currently active revision folder, e.g., 815. By default, every snap will use a symlink current , pointing to the latest available revision.
Directory structure - notable directories
~/snap/teams-for-linux/
├── 815/ # Data for revision 815 (active snap version)
│ ├── .config/ # Application-specific configuration path
│ │ └── teams-for-linux/ # Main config directory for Teams (Electron-based)
│ │ ├── Cookies # Chromium SQLite cookie store (login/session tokens)
│ │ ├── Cookies-journal # Write-ahead log for the Cookies DB
│ │ ├── Session Storage # Temporary session key-value store
│ │ ├── Local Storage # Persistent web storage (LevelDB backend)
│ │ ├── DIPS # Domain Interaction Points (site activity tracker)
│ │ ├── Cache # General web resource cache (images, scripts, etc.)
│ │ └── Partitions/ # Isolated browser contexts (webviews/embeds)
│ │ └── teams-for-linux/ # Default embedded session partition
│ │ ├── Cookies # Webview-specific cookies
│ │ ├── Cookies-journal # Write-ahead log for webview cookies
│ │ ├── Session Storage # Temp session data for embedded views
│ │ ├── DIPS # (Detect Incidental Party State)Activity tracking within embedded content
│ │ ├── Cache # Cached assets in embedded browser context
│ │ ├── Local Storage/ # Persistent local storage (LevelDB)
│ │ │ └── leveldb/ # Key-value storage used by Teams web app
│ │ ├── Session Storage/ # Session-specific data storage
│ │ └── IndexedDB/ # Structured application storage (IndexedDB)
│ │ ├── https_teams.live.com_0.indexeddb.leveldb
│ │ └── https_teams.microsoft.com_0.indexeddb.leveldb
├── common/ # Shared data (logs, settings) across all revisions
├── current -> 815/ # Symlink pointing to the active revision folder
The Partitions folder under the <revision> (with current as a symlink) directory is an absolute DFIR goldmine — brimming with Cookies, chats, meetings, tenant info and other forensic artifacts — that’s what we’re after.
Enough of the background—let’s deep dive into parsing each of these artifacts for practical DFIR use cases. let’s begin with one of the valuable sources of evidence: the cache files generated by teams-for-linux.
Artefact Extraction
Parsing Cache
Modern web browsers, including Chromium-based ones, cache resources such as images, JavaScript files, HTML pages, and media content to improve performance, reduce bandwidth usage, and enhance the overall user experience. Similarly, teams-for-linux—a wrapper around the Microsoft Teams web interface—leverages Chromium’s Simple Cache backend to store cached web content locally. This caching mechanism allows the application to load content faster and operate more efficiently by avoiding repeated network requests for frequently accessed resources.
Before we begin parsing these cached files, it’s important to understand the internal structure of the Cache files and the mechanics of how the Simple Cache backend operates. As per chromium documentation Like the older blockfile disk cache format, all the cache data is stored inside a single directory (~/snap/teams-for-linux/815/.config/teams-for-linux/Partitions/teams-4-linux/Cache/Cache_Data).
~/snap/teams-for-linux/current/.config/teams-for-linux/Partitions/teams-4-linux/Cache/Cache_Data/
├── index # Fake index (24 bytes) – unused
├── index-dir/
│ └── the-real-index # Real cache index (hash table)
├── 80ccd744f372388c_0 # Cache-Entry Files: Cached content file
├── 7bda832f185e1440_0 # Another cached content file
├── 5a9c32ab5d081c3e_s # Data stream files
├── ...
The directory contains a fake index file, several cache entry files, and the-real-index file located inside the index-dir folder.
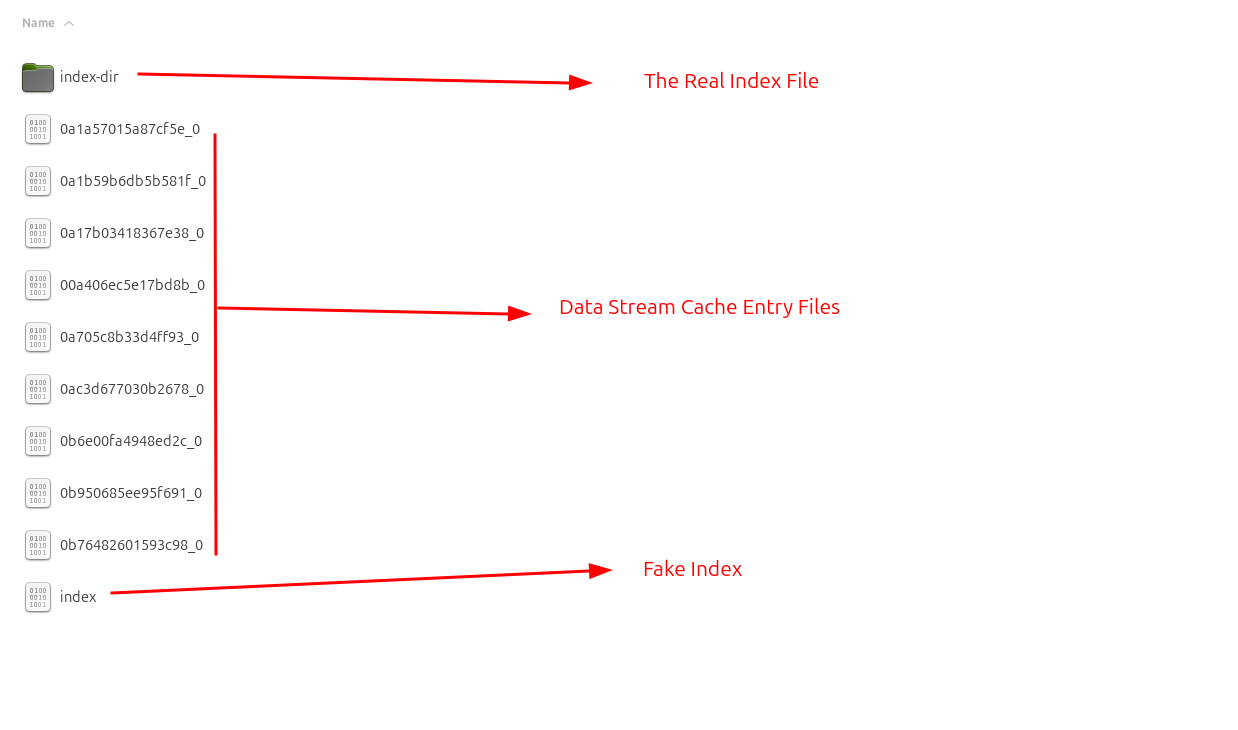
Where does the juicy info reside? It resides in the cache entry files (ending with _0 or _s) shown above. These files contain HTTP request/response data, JavaScript files, images, URLs,mp4,mp3,wav and more.
Then what about the real index file? To track these files effectively, the the-real-index file comes into play. This file maintains a list of all cache entry files along with their metadata, helping map and manage the cache content efficiently.
The real index file.
The-real-index file contains hash keys(cache addresses) for each cache entry. In simple terms the the-real-index file acts as a central record that keeps track of all cached entries(the real cache files which may contain images, url requests, responses, etc.). You can think of the real-index as a database or catalog of everything stored in the cache, while the cache entries themselves are the real items stored on disk.
Cache Entry Files - Actual Cache Items
Each cache entry is stored as its own seperate file named by the Entry Hash(Hash Key) in hexadecimal, an underscore(), and the backend stream number. A cache entry file is named using the reversed entry hash from the _the-real-index file, represented in hexadecimal, followed by an underscore and a stream number—either 0, 1, or s. In our case with teams-for-linux, files with stream number 0 are the most prevalent and typically hold the main cached content. There are two kinds of entries that can be stored:
- regular:
- xxxxxxx_0 Stores the HTTP response headers and sometimes small payload data for a cached resource such as thumbnails,icons etc.
- sparse:
- xxxxxxx_s Stores large or streamed payload data, such as media files or downloads, often in full or partial form.
Structure of the-real-index file.
Now let’s look at the structure of the the-real-index file, which tracks and maps all cached entries.
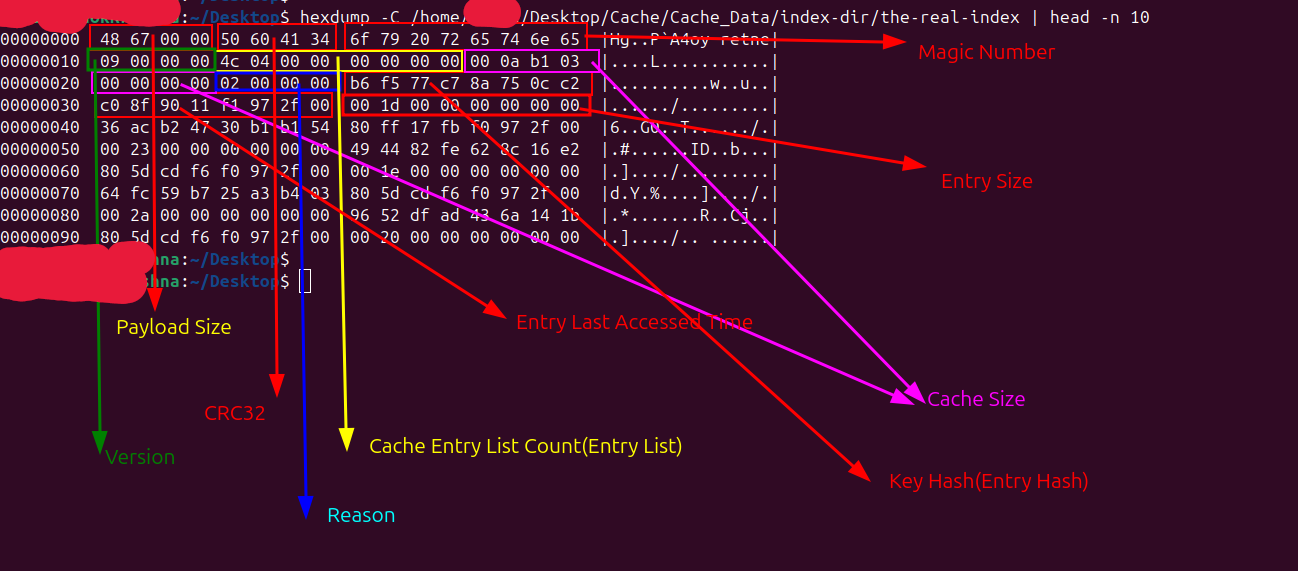
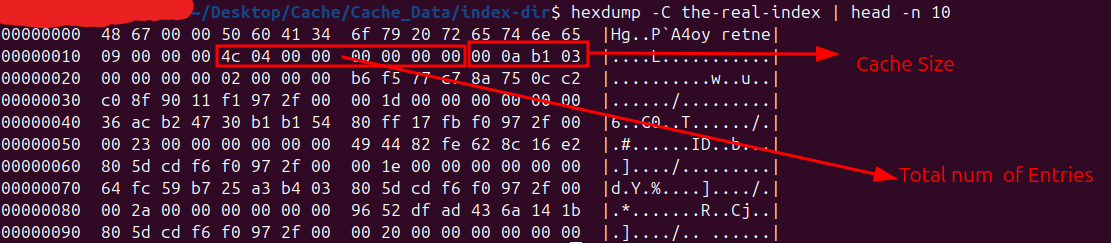
Notable information from the hexdump
| Offset | Field | Size(bytes) | Description |
|---|---|---|---|
| 0 | Payload Size | 4 | It defines the length of the serialized data (the payload) that follows the 8-byte header, allowing Chromium to safely read and validate the the-real-index file contents. |
| 4 | Payload CRC32 | 4 | A checksum used to verify the integrity of the file’s content. |
| 8 | MagicNumber | 8 | A unique identifier for the file, consistently set to 6F 79 20 72 65 74 6E 65 |
| 16 | Version | 4 | The version is a 4-byte value that indicates the file format version of the the-real-index structure, allowing Chromium to correctly interpret its contents. |
| 20 | Entries Count | 8 | Specifies how many individual cache entries are recorded in the file. |
| 28 | Cache Size | 8 | It represents the total size (in bytes) of all cache entries currently tracked in the index. |
| 36 | Write reason enum | 4 | reason is a debug or metadata field used internally by Chromium to indicate why or how a cache entry was created or updated |
| 40 | Hash Key(or Entry hash) | 8 | uniquely identifies a cached entry based on its key |
| 48 | Entry Last Used Time | 8 | It’s the last access time of a cache entry |
| 56 | Entry Size | 8 | Entry_size represents the total size in bytes of the single cache file (typically _0 or _s) associated with a given hash key, used for cache management and eviction decisions. |
| - | Last Cache Modified Time | 8 | The last 8 bytes of the the-real-index file contain a 64-bit integer value that represents The last known modification time of the cache folder. This value gets changed everytime the cache folder mtime changes. |
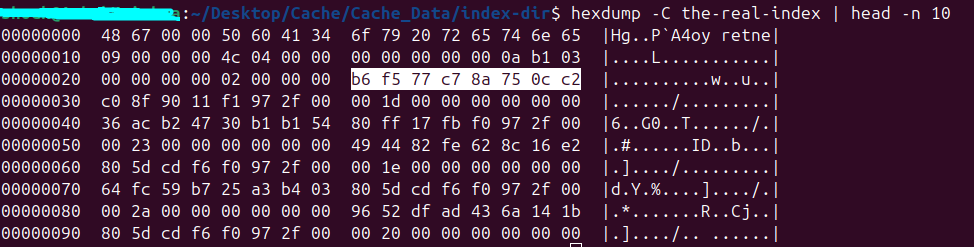
The the-real-index file begins with a 40-byte header, followed by a repeating sequence of 24-byte cache entry records, and ends with an 8-byte timestamp representing the cache directory’s last modified time. Each 24-byte cache entry consists of:
- an 8-byte Cache Entry Hash (derived from the URL),
- an 8-byte Last Used Time (indicating when the entry was last accessed),
- an 8-byte Entry Size (representing the size of the corresponding cache file).
In our case, the Version field in the the-real-index file confirms that Teams for Linux uses Chromium’s Simple Cache version 9 (v9). This means the structure of the-real-index—including fields like those shown in the table above—follows the v9 format and may differ if a different cache version is used.
Now, let’s take a closer look at some important fields from the the-real-index structure:
Payload Size:
The payload size is a 4-byte value at the beginning of the the-real-index file that indicates how many bytes come after the 8-byte header. It tells Chromium how much serialized index data (entries, metadata, timestamp) to read. This value helps ensure the file is complete and hasn’t been cut off or corrupted. In our case the payload size is 26440 bytes and the actual file size is 26448 which means the starting 8 bytes are only extra. So its matching successfully as shown.


NOTE: Everything after the first 8 bytes up to the end of the message is referred to as the payload.
What is this crc32?
Chromium verifies the integrity of this file by computing CRC32 over everything after the first 8 bytes and comparing it with the stored CRC. If the stored and computed CRC32 don’t match, the index is considered corrupted and may be rebuilt. Before DFIR analysis, verify the-real-index CRC32 to ensure the file isn’t corrupted or tampered with.

Cache Entry Count & Cache Size:
The the-real-index file stores metadata for indexed cache entries, including
- Entry Count: The total number of indexed cache entries
- Cache Size: It represents the total size (in bytes) of all cache entries currently tracked in the index
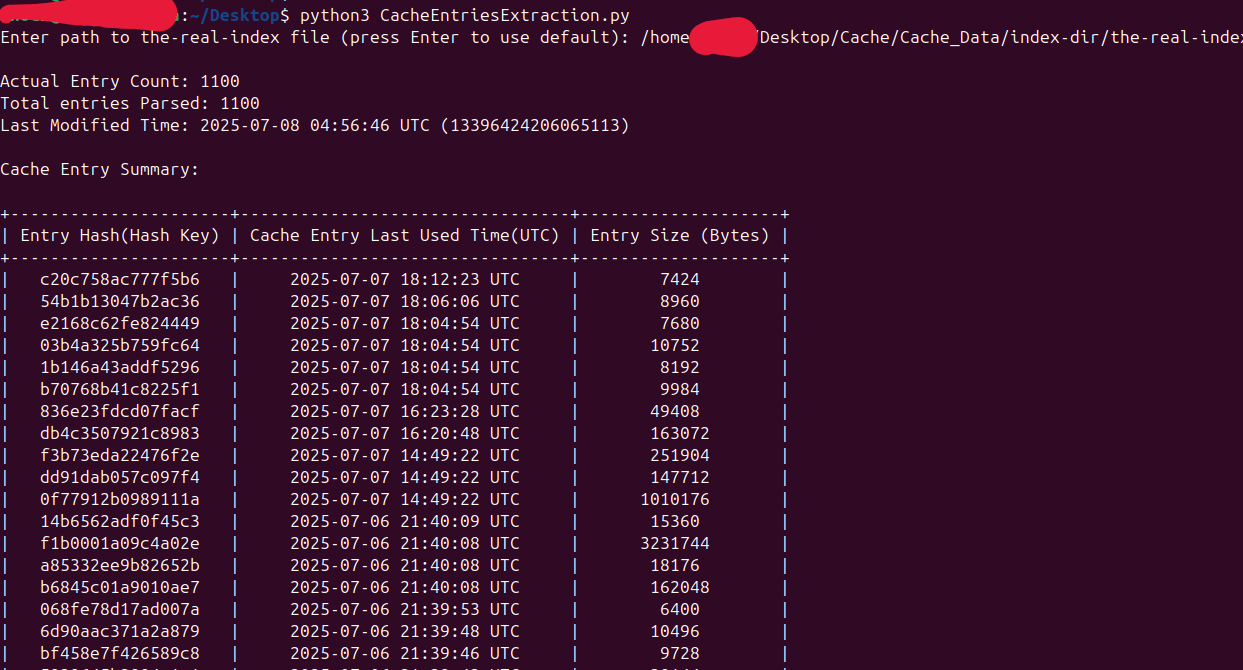
The image below shows that the total number of cache entries is 0x0000044C, which converts to 1100 in decimal — indicating that the the-real-index file is tracking 1100 cache entry files.
Note: I observed that both the Cache Entry Count (i.e., total number of entries) and the Cache Size recorded in the the-real-index file only account for _0 stream files, and do not include the presence or size of _s stream files (typically used for large media or downloads). in simple terms real index don’t track these xxxxxxx_s files.
Entry Hash
As mentioned earlier, from 40-byte header to till the final 8 bytes, the index file stores a list of cache entry records of 24-byte size, each record containing the Cache Entry Hash (Hash Key), Last Used Time, and Cache Entry Size. The Cache Entry Hash is a unique hexadecimal value that corresponds to the
Cache Entry Last Used Time:
In Chromium’s Simple Cache format (v9), the last_used_time represents the timestamp indicating when a cached entry (such as a URL resource) was last accessed. This value is stored as a 64-bit integer, denoting the number of microseconds since the Windows epoch (January 1, 1601 UTC), and is used internally to implement cache eviction strategies like Least Recently Used (LRU).
Cache Entry Size
The entry_size represents the total size of a cache entry file (typically _0 or _s) associated with a given cache entry, identified by a hash_key(Entry Hash). During cache recovery or directory scanning, Chromium calculates this size. If any file has an invalid or suspicious size (e.g., due to corruption), it defaults to a placeholder size of 32KB to maintain stability.
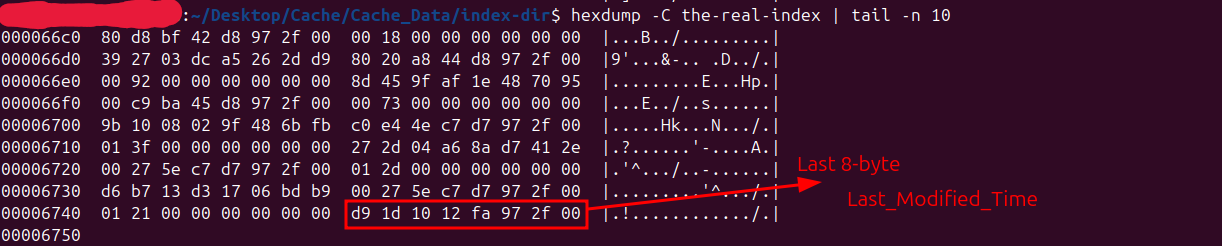
Last Cache Modified Time
The last 8 bytes of the the-real-index file store a 64-bit timestamp representing the modification time of the cache folder at the moment the index was written. This value is captured using the file system’s metadata and written via SerializeFinalData function. During index loading, Chromium reads this stored timestamp and compares it with the current modification time(mtime) of the cache directory. If the cache folder hasn’t changed since the index was saved, the index is considered fresh and used as-is; otherwise, it’s marked stale and rebuilt from disk.
Parsing the-real-index file conents
Parser’s up here. Download and run.
Structure of Cache Entry files.
Each cache entry file (_0) for Microsoft Teams on Linux begins with a fixed 24-byte header and ends with a fixed 24-byte footer. Between these, it sequentially contains the variable-length URL, Resource Content, and HTTP Response, optionally followed by a 32-byte SHA256 hash for the URL as shown. This is based on Version 5.
+------------------------------------------+
| 24-Byte Header |
| (e.g., Magic Number, Version, ) |
+------------------------------------------+
| |
| URL |
| (Variable Length) |
| |
+------------------------------------------+
| |
| Resource Content |
| (Variable Length) |
| (e.g., HTML, CSS, JavaScript, Image) |
| |
+------------------------------------------+
| |
| HTTP Response |
| (Variable Length) |
| (e.g., HTTP/1.1 200 OK, Content-Type) |
| |
+------------------------------------------+
| Optional SHA256 Hash (32-Byte) |
| (If integrity check is enabled/stored) |
+------------------------------------------+
| 24-Byte Footer |
| (e.g., EOF,CRC32,StreamSize) |
+------------------------------------------+
let’s examine each specific location (offset) to understand what data it holds and its purpose in the file. This helps us correctly read and interpret the file’s overall structure.
| Offset | Field | Size(bytes) | Description |
|---|---|---|---|
| 0 | MagicNumber | 8 | A unique identifier (magic value) for the file ####_0(Cached entry). |
| 8 | Version | 4 | Simple Cache format version - This version number defines the structure and layout of data within that particular cache file. |
| 12 | Key(URL) Length | 4 | Length of the URL in bytes. |
| 16 | Key Hash | 4 | The key_hash in Chromium’s disk cache is a non-cryptographic hash of the resource’s URL(key), calculated using Paul Hsieh’s SuperFastHash algorithm. It serves as a lightweight, fast lookup mechanism to locate cached data, prioritizing speed over the strong collision resistance and security features found in cryptographic hashes like SHA-256. |
| 20 | Unused Padding | 4 | Reserved |
| 24 | URL(key) | Key Length | The actual cached URL for the resource (e.g., JS, image, etc.). |
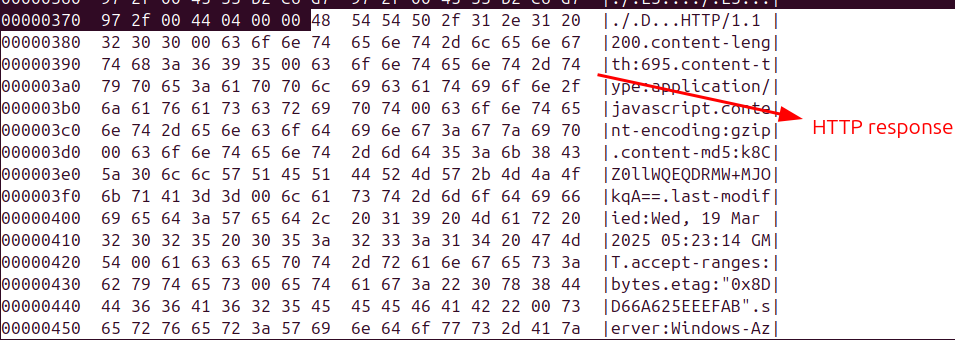
| - | Resource Content | The “Resource Content” field stores the resource’s raw data, often compressed (e.g., Gzip) for efficiency, but it can also directly contain uncompressed binary formats like JPG and other image types. | |
| HTTP Response | Contains the raw HTTP response data, with headers | ||
| Optional SHA256Hash | 32 | The 32-byte SHA256 hash is calculated on the key bytes, which start immediately after the 24-byte SimpleFileHeader.This hash is stored just before the EOF in stream_0 if FLAG_HAS_KEY_SHA256 is set. | |
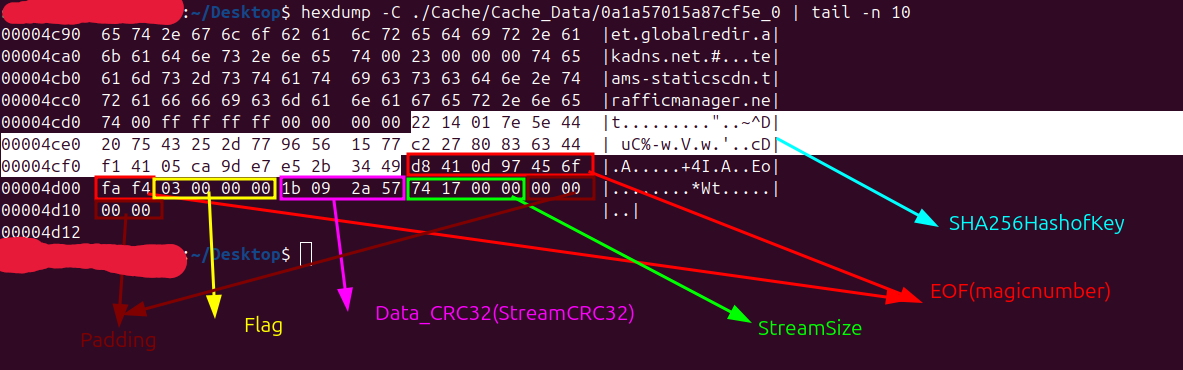
| EOF(final magic number) | 8 | Marks the end of a cache entry stream. This value is typically constant and used as a delimiter in the cache structure D8 41 0D 97 45 6F FA F4 | |
| Flag | 4 | flag = 0x01 → only CRC32 present. flag = 0x01 → only SHA256 present flag = 0x03 → CRC32 and SHA256 present | |
| data_crc32(stream crc32) | 4 | It stores the CRC32 checksum of the stream data (The contents of the stream stored inside the file. usually starting right after the URL key) in a cache entry file (_0,_s) and is used to verify the integrity of the stored content. | |
| StreamSize | 4 | stream_size is only used in the EOF record for stream 0. everything between the end of key and the start of footer | |
| Unused Padding | 4 | Unused Padding |
This is the first 24 bytes from a hexdump of a sample xxxxx_0 stream file
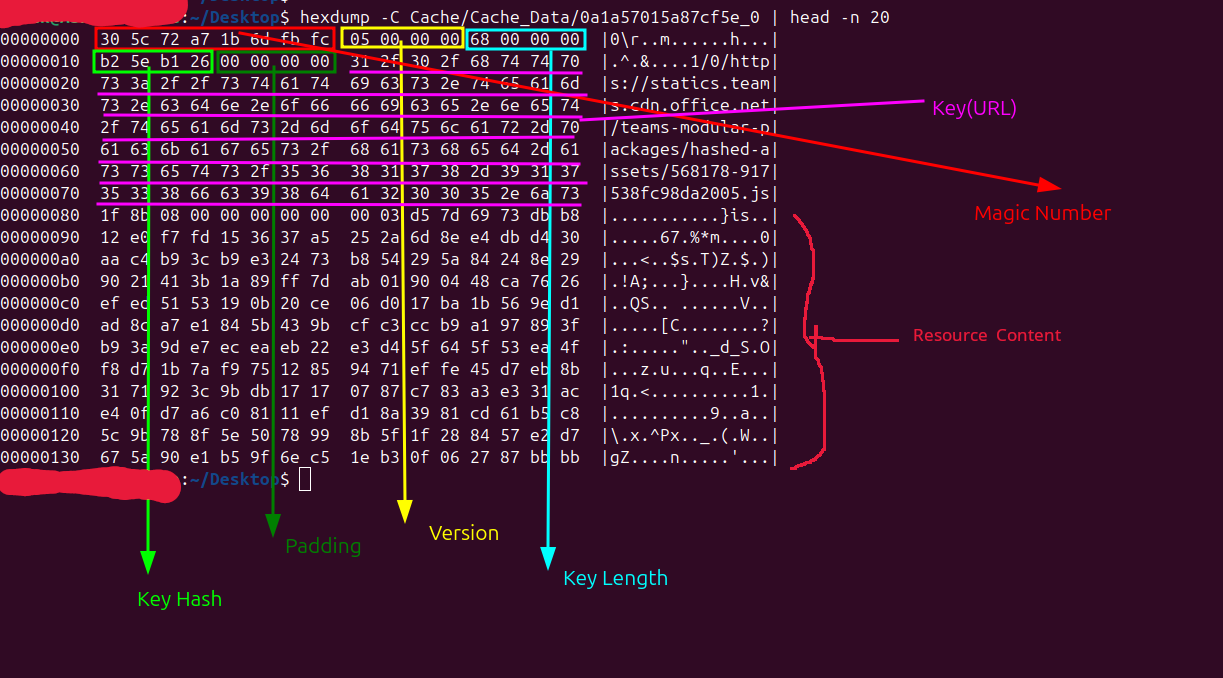
Note: The cache key(URL) includes the 1/0/ prefix, and this prefix is counted in the total URL length value stored in the entry.
The HTTP response is located in the middle section of the cache entry file.
Footer section of 24-bytes data shown below:
Before parsing the Cache Entry Files let’s take a closer look at some important fields from the xxxxxxx_0(Cache Entry) file structure:
teams-for-linux cache *_0 files primarily store the HTTP request URL, along with the corresponding HTTP response headers and response body (resource content). These three components form the core data of forensic and analytical interest.
The additional fields — including the header, footer (EOF record), and optional SHA256 — serve to structure, validate, and optimize how this core content is stored and retrieved efficiently. Chromium reads from the bottom of cache files to quickly access the EOF records, which contain essential metadata such as stream_size, flags, and Stream CRC32 related to the stream data which are used for
- Validate stream integrity using CRC32 checksums.
- Identify optional fields like SHA256 hashes via flags.
- Determine the location and length of stream data using stream_size.
Now, let’s take a sample cache entry file (_0) and verify the stream data using the footer values (like CRC32 and SHA256) with the help of a custom script. You can find the script here: cache_entry_verifier.py. Simply run the script on any cache entry ending with _0, as shown below, to perform the validation. Run the script on any cache entry with _0 file as shown.
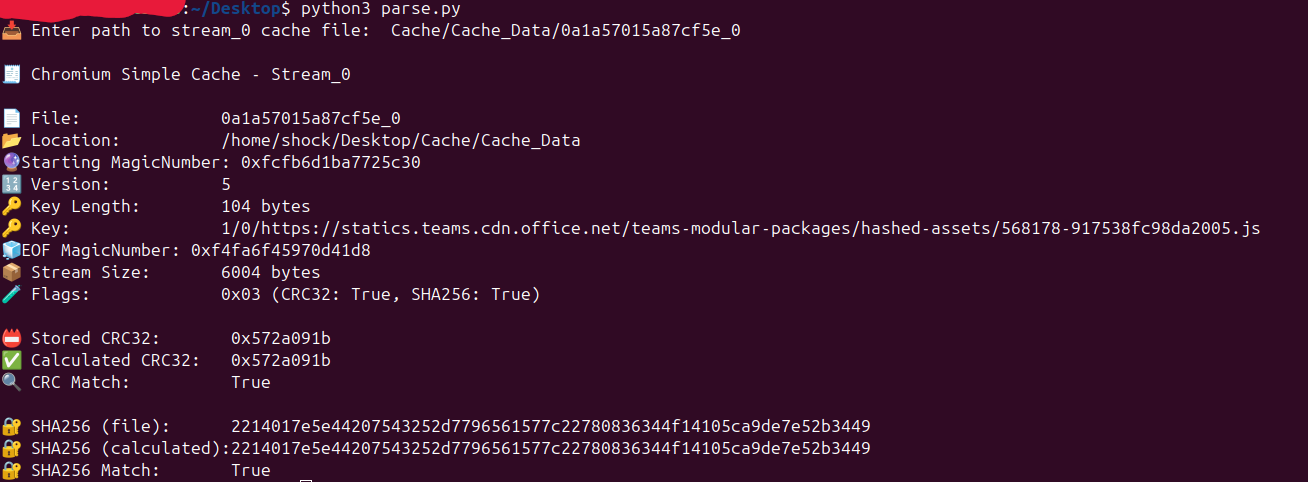
By reading the cache file from bottom to top, the script first parsed the EOF values such as StreamSize, CRC32 and SHA256. It then verified the stream data against these values, confirming that the data integrity is intact and everything was written correctly.
Resource Content
This is the raw content retrieved from the HTTP response. It may include images, icons, JavaScript files, emojis, profile pictures, meeting recording thumbnails, SSL/TLS certificates, and other embedded resources. Resource content is placed after the URL and before the HTTP response so let’s parse this data using the python script
What kind of artifacts can we extract from the cache files?
The cache contains all the images shared over chats or channels, including link previews, recorded video thumbnails, icons, emojis, and profile pictures, javascript files, http response, ssl/tls certificates etc. I have created a Python 3 script to extract images from the cache folder as shown. I found that only these files have forensic value, as most of the others are related to Teams or Microsoft domains and are mainly used for performance purposes
Download the code from here
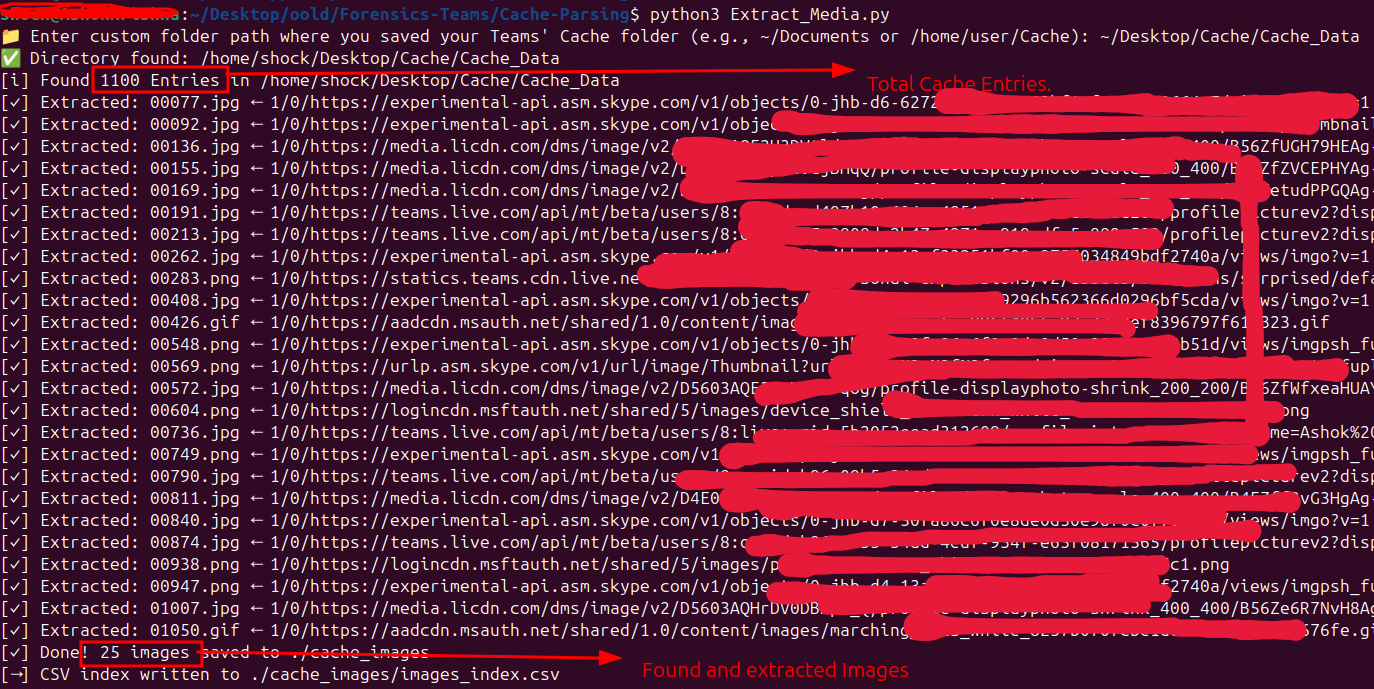
Run the python3 script to extract the Images as shown:
As shown, the total number of cache entries (1100) matches our earlier header analysis(the-real-index). In this example, the script successfully extracted 24 images from the cache entry file.
The extracted images are shown below. They include the thumbnail of a call recording, red-masked profile pictures of meeting participants (masked for privacy), my own profile picture, emojis from posts I reacted to, and sample images I shared in my personal chat.
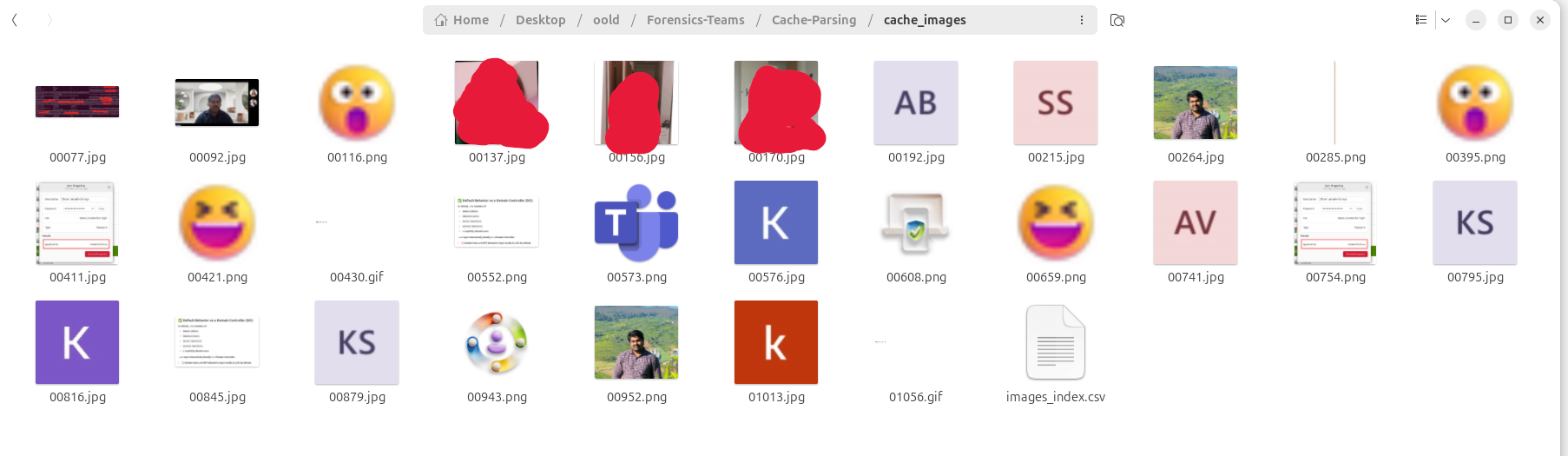
Note: The above output displays more than 25 items because additional changes were made later to demonstrate that emojis(reactions give to chat conversation) are also recorded.
If you want to extract all other files — including HTTP responses, JavaScript files, and more — you can use this script. However, since these artefacts have limited relevance for our DFIR analysis, I’ve chosen not to highlight them in detail here.
Sparse Range Files
Now, let’s take a look at another type of cache entry file — the _s files.
| Offset | Field | Size(bytes) | Description |
|---|---|---|---|
| 0 | MagicNumber | 8 | A unique identifier (magic value) for the file ####_s(Cached entry). |
| 8 | Version | 4 | Simple Cache format version - This version number defines the structure and layout of data within that particular cache |
| 12 | Key Length | 4 | Length of the URL in bytes. |
| 16 | Key Hash | 4 | The key_hash in Chromium’s disk cache is a non-cryptographic hash of the resource’s URL(key), calculated using Paul Hsieh’s SuperFastHash algorithm. It serves as a lightweight, fast lookup mechanism to locate cached data, prioritizing speed over the strong collision resistance and security features found in cryptographic hashes like SHA-256. |
| - | Key(URL) | Key Length | The actual cached URL for the resource (e.g., JS, image, etc.). |
| - | SparseRangeMagic | 8 | unique identifier for the sparse stream header |
| - | offset(StreamOffset) | 8 | The StreamOffset starts at 0 and increments by the value of StreamLength for each subsequent stream, i.e., each new StreamOffset is calculated as the previous StreamOffset + StreamLength. Allowing precise calculation of where each stream begins.” |
| - | length(StreamSize) | 8 | Total Stream Size |
| - | data_crc32 | 4 | CRC32 checksum for validating the stream |
| - | unknown | 4 | unknown bytes |
Chromium sparse cache files (_s files) begin with a 24-byte entry header containing the magic number, version, key length, and key hash. This is followed by the URL (key), whose length is defined in the header. After that, one or more 28-byte sparse range headers appear — each representing a data block with details like offset, length, and CRC32. These blocks are used to reconstruct the full cached content.
Some _s files contain only a single stream, while others include multiple streams. Multiple streams indicate the presence of multiple sparse range headers, each followed by its corresponding data block. These headers collectively describe how to piece together the full cached content from separate fragments.
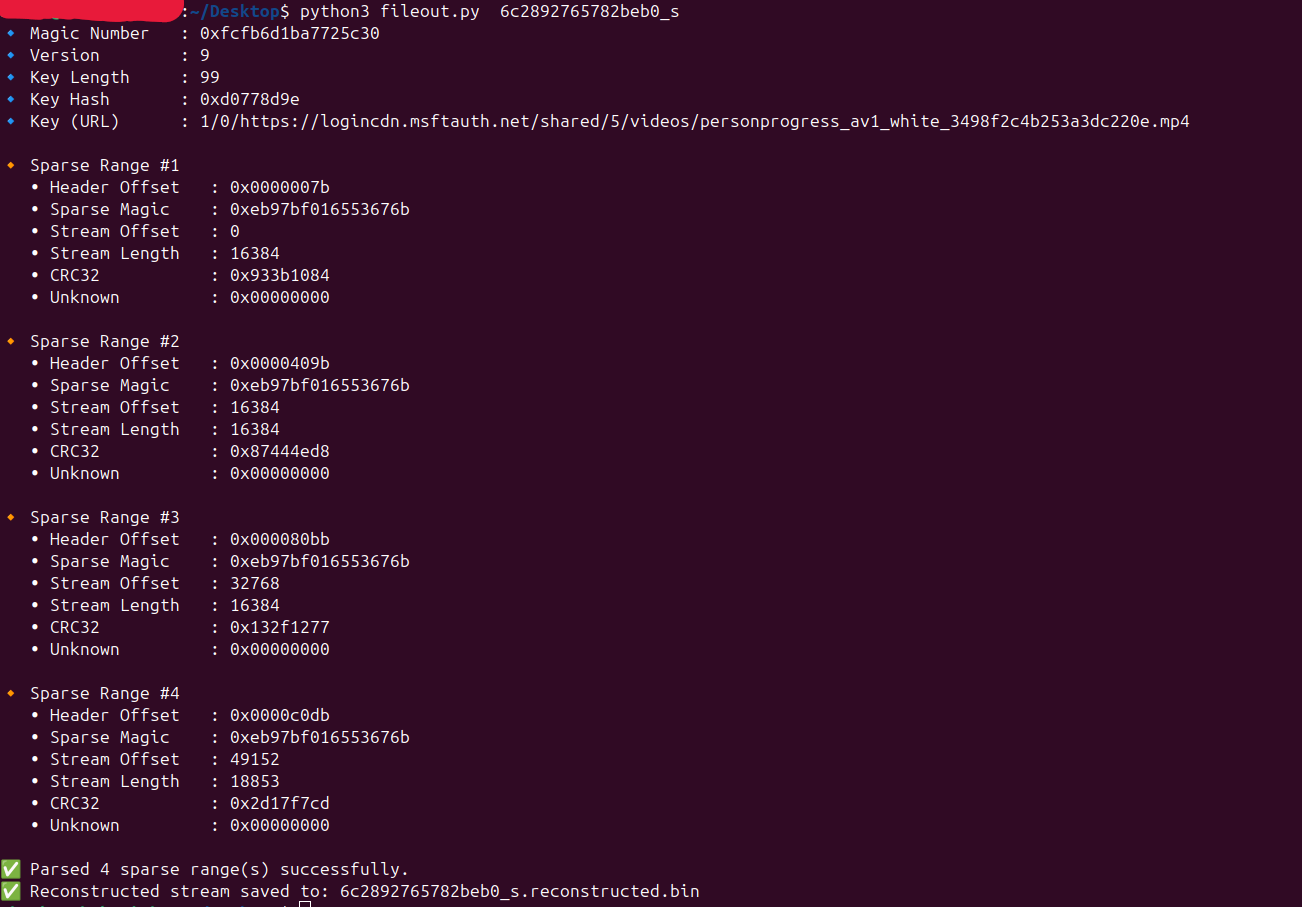
You can easily determine how many SparseRangeHeaders are present in a _s file by grepping for the starting magic number, as shown below:
>xxd -p xxxxxxx_s | tr -d '\n' | grep -o '6b67536501bf97eb'

For example, in the file shown above, there are a total of 4 SparseRangeHeaders. Let’s automate the reconstruction process by piecing them together. After each 28-byte header (plus 4 unknown bytes), the stream data begins at the specified offset and continues for the length defined in the header(streamlength field). The process repeats for each stream, collecting all fragments sequentially. Once combined, the full content is extracted to a file.
Since we’re working in a Linux environment, even though the extracted files don’t have proper file extensions, they still function correctly — most applications can recognize and open them based on their internal file signatures as shown. Opening the file opens an MP4 file as shown below.

This file was came from the following url

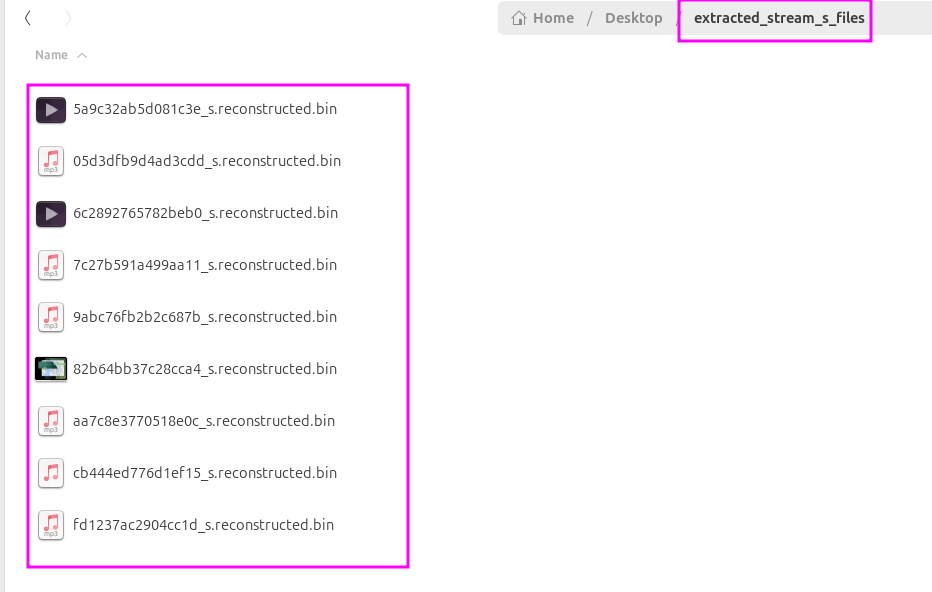
I’ve written a complete script that parses all s stream files from a given directory, extracts the sparse stream data, and reconstructs it. The output files are saved neatly into a _./extracted_stream_s_files/ folder for easy analysis as shown below. download the script from here
What next?
In the second part of this article, we’ll dive into how to decrypt cookies, read log files, and parse LevelDB data. We’ll also explore techniques to recover artefacts from Teams for Linux, even in cases where it was uninstalled — whether by an attacker or due to accidental removal.
References:
- https://chromium.googlesource.com/chromium/src/%2B/HEAD/net/disk_cache
- https://chromium.googlesource.com/chromium/src/net/+/e7109f535f4731976db6c26810b7176cfc851a6c/disk_cache/simple/simple_index_file.cc
- https://chromium.googlesource.com/chromium/src/%2B/20e724dd153bae2b4656435513bfc609e63299e5/net/disk_cache/simple/simple_synchronous_entry.cc
- https://chromium.googlesource.com/chromium/src/+/HEAD/net/disk_cache/simple/simple_index.h
- https://cocalc.com/github/chromium/chromium/blob/main/components/persistent_cache/entry_metadata.h